The structural organization of GEP genes is better understood in terms of open reading frames (ORFs). In biology, an ORF or coding sequence of a gene begins with the ‘start’ codon, continues with the amino acid codons, and ends at a termination codon. However, a gene is more than the respective ORF, with sequences upstream the start codon and sequences downstream the stop codon. Although in GEP the start site is always the first position of a gene, the termination point
does not always coincide with the last position of a gene. It is common for GEP genes to have non-coding regions downstream the termination point. For now we won’t consider these non-coding regions, because they don’t interfere with the product of expression.
Consider, for example, the algebraic expression:
|
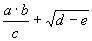
|
(2.1) |
It can also be represented as a diagram:
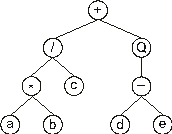
where ‘Q’ represents the square root function.
This kind of diagram representation is in fact the phenotype of GEP chromosomes, being the genotype easily inferred from the phenotype as follows:
|
0123456789 |
|
|
+/Q*c-abde |
(2.2) |
which is the straightforward reading of the ET from left to right and from top to bottom (exactly as we read a page of text). The expression
2.2 is an ORF, strarting at ‘+’ (position 0) and terminating at ‘e’ (position 9). I named these ORFs K-expressions (from Karva notation).
Consider another ORF, the following K-expression:
|
012345678901 |
|
|
*-/Qb+b+aaab |
(2.3) |
Its expression as an ET is also very simple and straightforward. To correctly express the ORF, we must follow the rules governing the spatial distribution of functions and terminals. First, the start of a gene corresponds to the root of the ET, forming this node the first line. Second, depending on the number of arguments to each element (functions may have a different number of arguments, whereas terminals have an arity of zero), in the next line are placed as many nodes as there are arguments to the functions in the previous line. Third, from left to right, the nodes are filled, in the same order, with the elements of the gene. Fourth, the process is repeated until a line containing only terminals is formed. So, for the K-expression
2.3 above, the root of the ET is the symbol at position 0, obtaining:

The multiplication function has two arguments, so the next line will have two nodes, in this case, the symbols at positions 1 and 2:
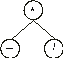
The subtraction and division are functions of two arguments, and therefore in the next line are placed four more nodes. In this case, the symbols at positions 3, 4, 5, and 6:
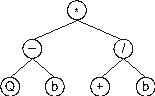
Now we have two different functions in the third line: one is a function of one argument (Q), and another a function of two arguments (+). Therefore three more nodes are required in the next line. In this case, they are filled with the elements at positions 7, 8, and 9:
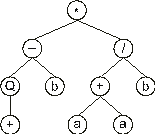
In this new line, although there are three nodes, only one of them is a function (+). Again, the required nodes are placed below that function and filled with the next elements in the ORF (positions 10 and 11), obtaining:
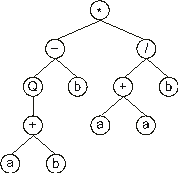
In this case, with this step the ET was completely formed as the last line contains only nodes with terminals. We will see that, thanks to the structural organization of GEP genes, the last line of all ETs contains exclusively terminals. This is equivalent to say that all GEP ETs are syntactically correct.
Looking at the structure of GEP ORFs only, it is difficult or even impossible to see the advantages of such a representation, except perhaps for its simplicity and elegance. However, when ORFs are analyzed in the context of a gene, the advantages of this representation become obvious. As I said, GEP chromosomes have fixed length, and they are composed of one or more genes of equal length. Therefore the length of a gene is also fixed. Thus, in GEP, what varies is not the length of genes which is constant, but the length of the ORFs. Indeed, the length of an ORF may be equal
to or less than the length of the gene. In the first case, the termination point coincides with the end of the gene, and in the last case, the termination point is somewhere upstream the end of the gene.
So, what is the role of these non-coding regions in GEP genes? They are in fact the essence of GEP and evolvability, for they allow the modification of the genome using any genetic operator without restrictions, producing always syntactically correct programs without the need for a complicated editing process or highly constrained ways of implementing genetic operators. Indeed, this is the paramount difference between GEP and previous GP implementations, with or without linear genomes.
Let’s analyze then the structural organization of GEP genes in order to understand how they invariably code for syntactically correct programs and why they allow an unconstrained application of any genetic operator.
|